Tissue Microarray
Contents
TMA-DDLM: Tissue Microarray Analysis via A Deep Dictionary Learning Method
Introduction
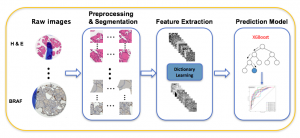
TMA-DDLM is a algorithm used to extract morphological features from Tissue Microarray images and make predictions for the important clinical parameters. Specifically, image features are extracted by deep dictionary learning method, which will be combined with the demographic covariates and make the final prediction by XGBoost.
This is a joint work with Prof. Hongtu Zhu.
Questions
1. Can we find the discriminative patch to represent each individual image when we do not have good notations in the patch level?
2. Can we get a low dimensional representations for the high-resolution level images?
Methods
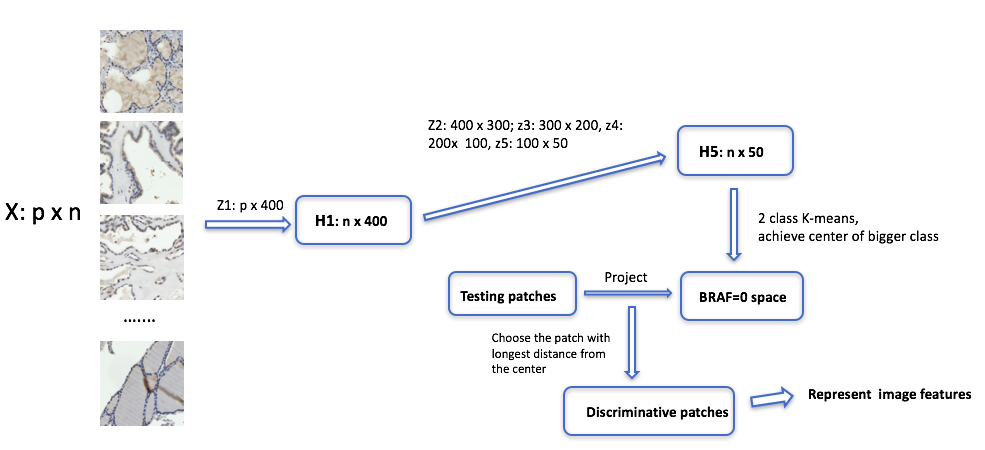
Step1: We use a deep dictionary learning method to find the most discriminative patch from each individual image and build a low dimensional representation of the selected patch to denote the features of the ‘mother’ images. Specifically, we choose all the patches extracted from the ‘normal’ images and produce a low dimensional representation for each patch by applying a five-layer dictionary learning model. It allows us to build a ”normal’ space, where the ‘normal’ space is constructed by all the patches which are classified into the bigger class by running a 2-class K-Means on all subjects in the low-dimension space. Subsequently, we project all the patches corresponding to all ‘normal’ and ‘abnormal’ images onto the ‘normal’ space and find the most discriminative patch of each image, which has the longest distance from the center of the ‘normal’ space. Since all patches are already mapped onto a low-dimensional space, we will use the low-dimensional representation of the ‘discriminative’ patches, which has a much smaller dimension compared to original patch, in order to represent the key features of their ‘mother’ images.
Step2: The extracted image features from Step1 along with the demographic covariates are used as predictors to predict the important clinical parameters of interest. We use XGBoost as the classification algorithm, which is a tree-based boosting algorithm for training a predictive model and selecting important covariates. Before training the prediction model, we sort all the features according to their marginal correlation with the outcome and sequentially add predictors until the overall AUC value does not increase within a certain number of steps to prevent over-fitting when learning the XGBoost structure. Then we iteratively drop out the features considered unimportant by XGBoost until convergence and use the predictive model with remaining covariates to do the final prediction.
Findings
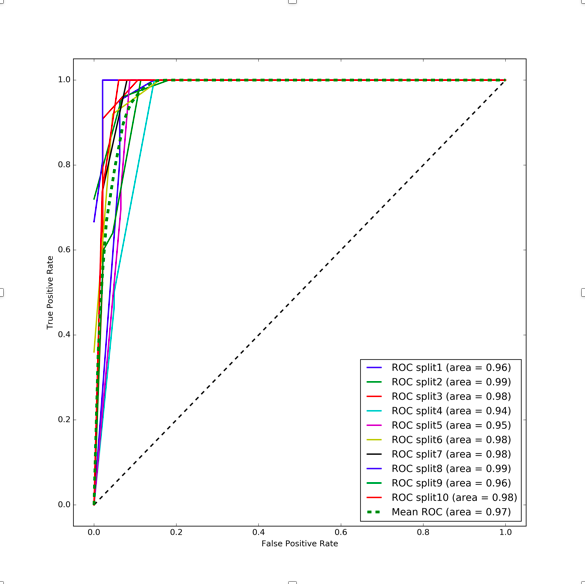
According to the results by applying our method on real data analysis, TMA-DDLM can provide an acceptable prediction accuracy of the responses of interest. Although there is a lack of precise patch-level annotation, TMA-DDLM can automatically find the discriminative regions.
References
1. Trigeorgis, G., Bousnalis, K., Zafeiriohu, S., and Schuller, B. W. (2017). A deep matrix factorization method for learning attribute representations. IEEE transactions on pattern analysis and machine intelligence, 39(3): 417-429.
2. Chen, T. and Guestrin, C. (2016). Xgboost: A scalable tree boosting system. In Proceeding of the 22Nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 785-794. ACM.